
![]()
Team
|
Scope of research
- computational linguistics
- natural language engineering
- language technology
- lexicography
- e-learning infrastructure
Competences
- automatic Polish and English texts analysis on morphological, syntactic, and semantic levels
- construction of lexico-semantic networks, dictionaries, thesauri, wordnets
- construction of bilingual lexico-semantic networks and dictionaries
- construction of text corpora described by meta-data on various linguistic levels
- semantic classification and clustering of texts
- construction of shallow (syntactic and semantic) parsers for Polish
- extraction of data:
- recognition and classification of named entities
- generation of dictionaries of named entities
- recognition of temporal and spatial expressions
- recognition of semantic relations and situation elements
- recognition of co-reference for named entities
- extraction of knowledge from texts (Text Mining): a combination of knowledge extraction and Data Mining
- shallow statistical semantic analysis of texts (distributional semantics)
- distributed text processing
- construction of distributed research infrastructure
- application of formal methods of analysis and representation of text meaning
- extraction of keywords from texts
- application of natural language engineering methods to digital humanities and digital social sciences
- systems for collecting and editing text corpora
- meta-data standards for description of documents
- construction of research tools for lexicographic works
- semi-automatic construction of semantic networks based on a collection of texts
- open question answering systems in a natural language
- application of natural language engineering methods to information retrieval
- application of natural language engineering methods to humanities and social sciences
Projects
- plWordNet 1.0 (Słowosieć 1.0)
Automatic methods of constructing semantic network of Polish lexems for the purposes of natural language processing. 2005-10-30 to 2008-10-30 Number 3 T11C 018 29 366 900,00 PLN Leader Maciej Piasecki, PhD, Eng. - plWordNet 2.0 (Słowosieć 2.0)
Construction of lexical resources with the help of recognition of semantic relations in text corpora on the basis of morpho-syntactic and semantic data 2009-10-30 to 2012-10-30 Number N N516 068637 406 960,00 PLN Leader Maciej Piasecki, PhD, Eng. - NEKST
Adaptive system supporting solving problems on the basis of content analysis of electronic documents 2010-01-01 to 2014-07-01 Number POIG.01.01.02-14-013/09 4 110 743,00 PLN (dla PWr) Leader Maciej Piasecki, PhD, Eng. - SyNaT
SyNaT: Research Task: “Construction of an open, repository hosting and communication platform for the network knowledge resources for science, education and open knowledge society” 2010-08-16 to 2014-07-31 Number POIG.01.01.02-14-013/09 2 800 000,00 PLN Leader Maciej Piasecki, PhD, Eng. - CLARIN-PL
CLARIN-PL: Polish part of the CLARIN ERIC research infrastructure Common Language Resources and Technology Infrastructure 2013-01-01 to 2015-04-30 Number 6358/IA/119/2013 16 500 000,00 PLN Leader Maciej Piasecki, PhD, Eng. - CLARIN-PL support
Designing research methodology for the development of CLARIN language technology infrastructure and disseminating CLARIN research infrastructure. 2015-02-16 to 2016-04-30 Number 3255/CLARIN ERIC/2015/0 1 000 000,00 PLN Leader Maciej Piasecki, PhD, Eng.
Significant achievements

- CLARIN-PL Language Technology Center – the Polish section of the pan-European research infrastructure CLARIN ERIC. The center stores, renders accessible and disseminates services, tools and resources for Polish language processing. It also technically coordinates CLARIN consortium in Poland.
![]()
- plWordNet (Słowosieć) – a large semantic dictionary of Polish and a Polish-English dictionary. plWordNet is a unique combination of a monolingual dictionary, a thesaurus, a bilingual dictionary, and a bilingual network of lexico-semantic relations. In its latest version, plWN comprises 165 000 words, 240 000 word meanings, over 500 000 relations, and 130 000 Polish-English entries. It is available as a free mobile application, Mobile plWordNet, on Google Play.
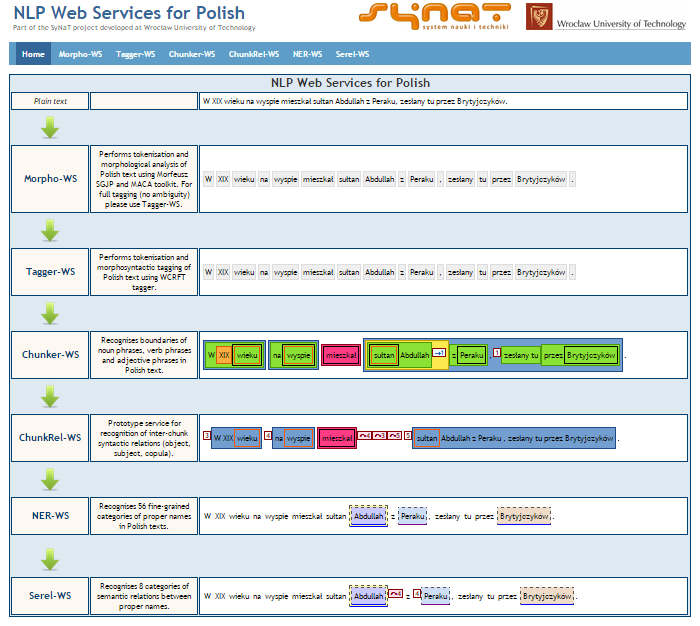

- KPWr – a Corpus of Polish Language of Wrocław University Technology (pl. Korpus Języka Polskiego Politechniki Wrocławskiej) is a corpus of written and spoken documents available on the Creative Commons license. The texts are divided into 14 categories corresponding to content types. They are manually annotated with respect to named entities and relations holding among them, temporal expressions, chunks, anaphora relations, and word senses, among others.
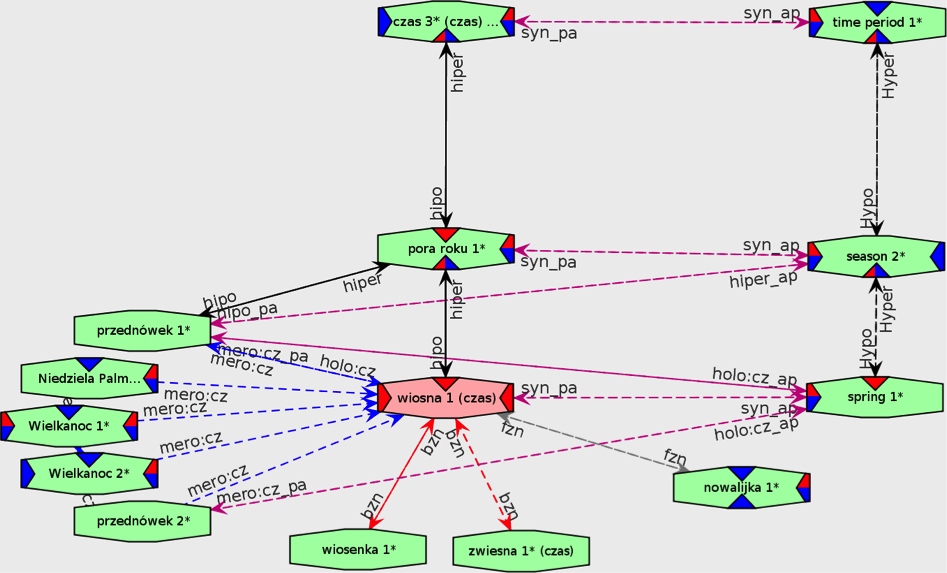
- WordnetWeaver – a semi-automatic system facilitating plWordNet expansion on the basis of data extracted from large text corpora, integrated with WordnetLoom, a system enabling visual edition of wordnet relation graphs.
![]()
- Inforex – a web system for text corpora construction. Inforex allows parallel access and sharing resources among many users. The system assists semantic annotation of texts on several levels, such as marking text references, creating new references, or marking word senses.
More important papers
Books
Piasecki, M.; Szpakowicz, S. & Broda, B. (2009), A Wordnet from the Ground Up, Oficyna Wydawnicza Politechniki Wrocławskiej, Wrocław,
URL: http://nlp.pwr.wroc.pl/download/A_Wordnet_from_the_Ground_Up.pdf
Journal papers
- Maziarz, M., Piasecki, M., Szpakowicz, S. (2013), The chicken-and-egg problem in wordnet design: synonymy, synsets and constitutive relations, “Language Resources and Evaluation” (IF = 0,518), 47 (3), 769-796. IF
- Maciej Piasecki, Stan Szpakowicz, Christiane Fellbaum, Bolette Sandford Pedersen: Introduction to the special issue: On wordnets and relations. Language Resources and Evaluation 47(3): 757-767 (2013) IF
- Bartosz Broda, Maciej Piasecki (2013) Parallel, massive processing in SuperMatrix: a general tool for distributional semantic analysis of corpora. International Journal of Data Mining, Modelling and Management, 5(1): 1-19
- Kędzia Paweł, Maciej Piasecki, Ewa Rudnicka, Konrad Przybycień. Automatic Prompt System in the Process of Mapping plWordNet on Princeton WordNet. Cognitive Studies Vol. 13, 2013.
- Piasecki Maciej. Self-organising logic of structures as a basis for a dependency-based dynamic semantics model. Cognitive Studies Vol. 13, 2013.
- Radziszewski, A., Maziarz, M., Wieczorek, J. (2012), Shallow syntactic annotation in the Corpus of Wrocław University of Technology, “Cognitive Studies / Etudes Cognitives” (lista ERIH), 12.
- Maziarz, M., Szpakowicz, S., Piasecki, M. (2012). Semantic Relations among Adjectives in Polish WordNet 2.0: A New Relation Set, Discussion and Evaluation. “Cognitive Studies / Etudes Cognitives” (lista ERIH), 12, s. 149-179.
- Marcińczuk, M. & Piasecki, M. (2011), ‚Statistical Proper Name Recognition in Polish Economic Texts’, Control and Cybernetics 40(2), 393-418. (IF w 2010)
- Broda, B. & Piasecki, M. (2011), ‚Evaluating LexCSD in a Large Scale Experiment’, Control and Cybernetics 40(2), 419-436.
- Radziszewski, A., Maziarz, M. (2011), Developing free morphological data for Polish, “Cognitive Studies / Etudes Cognitives” (lista ERIH), 11.
- Maziarz, M., Piasecki, M., Szpakowicz, S., Rabiega-Wiśniewska, J., Hojka, B. (2011), An Implementation of a System of Verb Relations in plWordNet 2.0, “Cognitive Studies / Etudes Cognitives” (lista ERIH), 11.
- Maziarz, M., Piasecki, M., Szpakowicz, S., Rabiega-Wiśniewska, J. (2011), Semantic Relations among Nouns in Polish WordNet Grounded in Lexicographic and Semantic Tradition”, “Cognitive Studies / Etudes Cognitives” (lista ERIH), 11.
- Broda, B.; Piasecki, M. & Szpakowicz, S. (2010) Extraction of Polish Noun Senses from Large Corpora by Means of Clustering. Control and Cybernatics 39 (2), pp. 401-420.
- Piasecki, M. (2010), ‚Automated Extraction of Lexical Meanings from Polish Corpora: Potentialities and Limitations’, Cognitive Studies Études Cognitives 10, 185–210.
- Broda, B.; Derwojedowa, M. & Piasecki, M. (2008), Recognition of Structured Collocations in An Inflective Language. Systems Science 34(4), 27–36.
- Piasecki, M. & Radziszewski, A. (2008), Morphological Prediction for Polish by a Statistical A Tergo Index. Systems Science 34(4), 7–17.
- Piasecki, M. (2007), Polish Tagger TaKIPI: Rule Based Construction and Optimisation. Task Quarterly 11(1–2), 151–167.