
![]()
Skład
Obszar badań
- lingwistyka informatyczna,
- inżynieria języka naturalnego,
- technologia językowa,
- leksykografia,
- infrastruktura naukowa dla e-nauki.
Kompetencje
- automatyczna analiza tekstów w języku polskim i angielskim: poziom wyrazowy, składniowy i semantyczny;
- budowa leksykalnych sieci semantycznych, słowników, tezaurusów, wordnetów;
- budowa dwujęzycznych leksykalnych sieci semantycznych i słowników;
- budowa korpusów tekstów opisywanych metadanymi na różnych poziomach lingwistycznych;
- klasyfikacja semantyczna i grupowanie tekstów;
- konstrukcja płytkich parserów (składniowych i semantycznych) dla języka polskiego;
- wydobywanie informacji:
- rozpoznawanie i klasyfikacja nazw własnych,
- generowanie słowników nazw własnych,
- rozpoznawanie wyrażeń temporalnych i przestrzennych,
- rozpoznawanie relacji semantycznych i elementów sytuacji,
- rorpoznawanie koreferencji dla nazw własnych,
- wydobywanie wiedzy z tekstów (Text Mining): połączenie wydobywania informacji i Data Mining
- płytka statystyczna analiza semantyczna tekstów (semantyka dystrybucyjna);
- rozproszone przetwarzanie tekstów;
- konstrukcja rozproszonej infrastruktury naukowej;
- zastosowanie metod formalnych do analizy i reprezentacji znaczenia tekstu;
- wydobywanie słów kluczowych z tekstu;
- zastosowania metod inżynierii języka naturalnego w cyfrowej humanistyce i cyfrowych naukach społecznych;
- systemy do gromadzenia i edycji korpusów tekstowych;
- standardy metadanych do opisu dokumentów tekstowych;
- konstrukcja narzędzi naukowych do prac leksykograficznych,
- półautomatyczna konstrukcja sieci semantycznych na podstawie zbioru tekstów
- systemy odpowiadania na pytania otwarte w języku naturalnym
- zastosowania metod inżynierii języka naturalnego w wyszukiwaniu informacji
- zastosowania metod inżynierii języka naturalnego w humanistyce i naukach społecznych
Projekty
- Słowosieć 1.0
Nazwa Automatyczne metody konstrukcji sieci semantycznej leksemów polskich na potrzeby przetwarzania języka naturalnego. Okres od 2005-10-30 do 2008-10-30 Numer 3 T11C 018 29 Kwota 366 900,00 PLN Kierownik dr inż. Maciej Piasecki - Słowosieć 2.0
Nazwa Konstrukcja zasobów leksykalnych przez rozpoznawanie relacji semantycznych na podstawie danych morfosyntaktycznych i semantycznych
w korpusach tekstu.Okres od 2009-10-30 do 2012-10-30 Numer N N516 068637 Kwota 406 960,00 PLN Kierownik dr inż. Maciej Piasecki - NEKST
Nazwa NEKST Adaptacyjny system wspomagający rozwiązywanie problemów w oparciu o analizę treści dostępnych źródeł elektronicznych. Okres od 2010-01-01 do 2014-07-01 Numer POIG.01.01.02-14-013/09 Kwota 4 110 743,00 PLN (dla PWr) Kierownik dr inż. Maciej Piasecki - SyNaT
Nazwa SyNaT: Zadanie badawcze „Utworzenie uniwersalnej, otwartej, repozytoryjnej platformy hostingowej i komunikacyjnej dla sieciowych
zasobów wiedzy dla nauki, edukacji i otwartego społeczeństwa wiedzy”Okres od 2010-08-16 do 2014-07-31 Numer POIG.01.01.02-14-013/09 Kwota 2 800 000,00 PLN (dla PWr) Kierownik dr inż. Maciej Piasecki - CLARIN-PL
Nazwa CLARIN-PL: „Polska część infrastruktury naukowej CLARIN ERIC: Wspólne zasoby językowe i infrastruktura technologiczna.” Okres od 2013-01-01 do 2015-04-30 Numer 6358/IA/119/2013 Kwota 16 500 000,00 PLN Kierownik dr inż. Maciej Piasecki(Polski Koordynator Narodowy z ramienia MNiSW) - CLARIN-PL wsparcie
Nazwa Opracowanie metodologii prac nad rozwojem infrastruktury technologii językowych CLARIN oraz upowszechnienie wytworzonej w ramach
CLARIN infrastruktury badawczej.Okres od 2015-02-16 do 2016-04-30 Numer 3255/CLARIN ERIC/2015/0 Kwota 1 000 000,00 PLN Kierownik dr inż. Maciej Piasecki
Osiągnięcia i wyniki

- Centrum Technologii Językowej CLARIN-PL — polski węzeł ogólnoeuropejskiej infrastruktury badawczej CLARIN ERIC. Centrum przechowuje, udostępnia i upowszechnia usługi, zasoby i narzędzia do przetwarzania języka polskiego. Koordynuje także na poziomie technicznym konsorcjum CLARIN w Polsce.
![]()
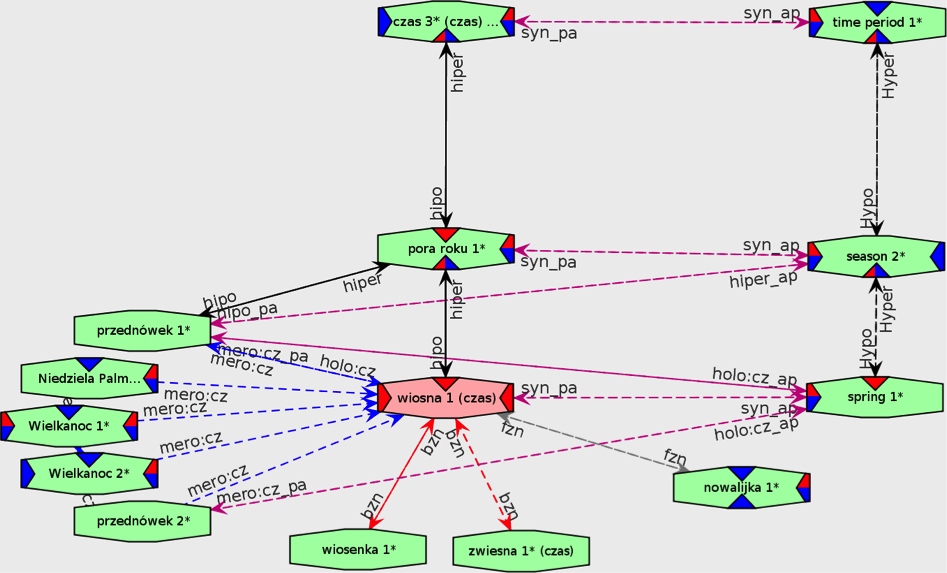
- Słowosieć — wielki słownik semantyczny języka polskiego, będący jednocześnie dużym słownikiem polsko-angielskim. Zasób ten stanowi unikalne połączenie słownika jednojęzycznego, słownika wyrazów bliskoznacznych (tezaurusa), słownika dwujęzycznego oraz dwujęzycznej sieci relacji leksykalno-semantycznych. W najnowszej wersji zawiera 165 000 słów, 240 000 znaczeń, ponad 500 000 relacji oraz 130 000 haseł polsko-angielskich. Jest dostępny także w formie darmowej aplikacji mobilnej — Mobile plWordNet na Google Play.
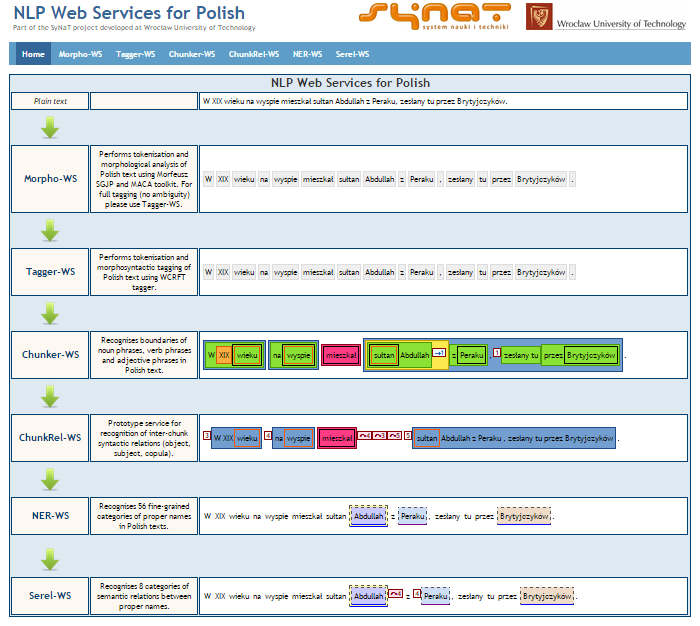

- Korpus Języka Polskiego Politechniki Wrocławskiej (KPWr) to korpus mówionych i pisanych tekstów udostępniony na licencji Creative Commons. Teksty zostały podzielone na 14 kategorii odpowiadających różnego typu komunikatom. Dokumenty zostały ręcznie oznakowane m.in. w ramach nazw własnych i relacji między nimi, wyrażeń temporalnych, chunków, relacji anaforycznych oraz znaczeń słów.
- WordnetWeaver — półautomatyczny system wspomagający rozszerzanie polskiego wordnetu w oparciu o dane wydobywane z wielkich korpusów tekstu zintegrowany z WordnetLoom systemem do edycji wordnetu umożliwiającym rozproszoną pracę zespołu lingwistów w oparciu o wizualną edycję grafów wordnetowych relacji
![]()
- Inforex — webowy system do konstrukcji korpusów tekstowych. Pozwala na równoległy dostęp wielu użytkowników oraz współdzielenie zasobów. System wspiera proces anotacji semantycznej tekstów na kilku poziomach, m.in. znakowanie odniesień tekstowych, tworzenie relacji między odniesieniami, znakowanie znaczeń słów.
Ważniejsze publikacje
Książki
Piasecki, M.; Szpakowicz, S. & Broda, B. (2009), A Wordnet from the Ground Up, Oficyna Wydawnicza Politechniki Wrocławskiej, Wrocław,
URL: http://nlp.pwr.wroc.pl/download/A_Wordnet_from_the_Ground_Up.pdf
Artykuły
- Maziarz, M., Piasecki, M., Szpakowicz, S. (2013), The chicken-and-egg problem in wordnet design: synonymy, synsets and constitutive relations, “Language Resources and Evaluation” (IF = 0,518), 47 (3), 769-796. IF
- Maciej Piasecki, Stan Szpakowicz, Christiane Fellbaum, Bolette Sandford Pedersen: Introduction to the special issue: On wordnets and relations. Language Resources and Evaluation 47(3): 757-767 (2013) IF
- Bartosz Broda, Maciej Piasecki (2013) Parallel, massive processing in SuperMatrix: a general tool for distributional semantic analysis of corpora. International Journal of Data Mining, Modelling and Management, 5(1): 1-19
- Kędzia Paweł, Maciej Piasecki, Ewa Rudnicka, Konrad Przybycień. Automatic Prompt System in the Process of Mapping plWordNet on Princeton WordNet. Cognitive Studies Vol. 13, 2013.
- Piasecki Maciej. Self-organising logic of structures as a basis for a dependency-based dynamic semantics model. Cognitive Studies Vol. 13, 2013.
- Radziszewski, A., Maziarz, M., Wieczorek, J. (2012), Shallow syntactic annotation in the Corpus of Wrocław University of Technology, “Cognitive Studies / Etudes Cognitives” (lista ERIH), 12.
- Maziarz, M., Szpakowicz, S., Piasecki, M. (2012). Semantic Relations among Adjectives in Polish WordNet 2.0: A New Relation Set, Discussion and Evaluation. “Cognitive Studies / Etudes Cognitives” (lista ERIH), 12, s. 149-179.
- Marcińczuk, M. & Piasecki, M. (2011), ‚Statistical Proper Name Recognition in Polish Economic Texts’, Control and Cybernetics 40(2), 393-418. (IF w 2010)
- Broda, B. & Piasecki, M. (2011), ‚Evaluating LexCSD in a Large Scale Experiment’, Control and Cybernetics 40(2), 419-436.
- Radziszewski, A., Maziarz, M. (2011), Developing free morphological data for Polish, “Cognitive Studies / Etudes Cognitives” (lista ERIH), 11.
- Maziarz, M., Piasecki, M., Szpakowicz, S., Rabiega-Wiśniewska, J., Hojka, B. (2011), An Implementation of a System of Verb Relations in plWordNet 2.0, “Cognitive Studies / Etudes Cognitives” (lista ERIH), 11.
- Maziarz, M., Piasecki, M., Szpakowicz, S., Rabiega-Wiśniewska, J. (2011), Semantic Relations among Nouns in Polish WordNet Grounded in Lexicographic and Semantic Tradition”, “Cognitive Studies / Etudes Cognitives” (lista ERIH), 11.
- Broda, B.; Piasecki, M. & Szpakowicz, S. (2010) Extraction of Polish Noun Senses from Large Corpora by Means of Clustering. Control and Cybernatics 39 (2), pp. 401-420.
- Piasecki, M. (2010), ‚Automated Extraction of Lexical Meanings from Polish Corpora: Potentialities and Limitations’, Cognitive Studies Études Cognitives 10, 185–210.
- Broda, B.; Derwojedowa, M. & Piasecki, M. (2008), Recognition of Structured Collocations in An Inflective Language. Systems Science 34(4), 27–36.
- Piasecki, M. & Radziszewski, A. (2008), Morphological Prediction for Polish by a Statistical A Tergo Index. Systems Science 34(4), 7–17.
- Piasecki, M. (2007), Polish Tagger TaKIPI: Rule Based Construction and Optimisation. Task Quarterly 11(1–2), 151–167.